


I miss writing some technical post. Hear my engineer part of me talking. Diving into it right away. Join my train of thoughts...
You are running systems under higher transactional load. You looked for all these fancy patterns out there to compliment your reliability guarantees for your services. Evented or not it doesn't matter, you will try to solve these anyway. You explored, maybe implemented some of them (e.g. transactional outbox1).
Awesome you are there for most of the things that is ready. You are using databases that does not have "self healing" capabilities, and working with them for years. You don't have a data fabric2, manually managing integrations. Moreover, you are working in a team that is close to company's data than any other team in the company. Your team consists of highly skilled engineers.
Mission critical systems require fast recovery, enough metadata (the infamous catalog), availability and performance. Everyone knows these are required. We don't use any specific technology embedded in our projects mostly. We try to offload these guarantees to well known projects like MySQL, Postgres, Kafka, Glue and more... Every tool has it's own capabilities, and our services sit in the middle.
That said, my free time goes into being an engineer to not forget the things I learned in these areas. Experimenting and developing new niche when time allows. I am being a director by day, by night I transform into code wizard mode.
In one of these nights, I realized services don't have embedded recovery system regardless of their language they are written. We rely purely external service guarantees, what happens if we have in-flight messages that hasn't been acknowledged yet while we are processing them? What happens if we want to combine multiple change streams into combined domain object on the flight for a long period of time but doesn't want to lose anything if we have a poison pill?3
Unreliability the Unseen
With stated both my and your teams most probable situation. I would like to share one of my experiences here.
Having this very much possible, in one of my experiences, with my team we had a Risk assessment system running for enormous amount of messages per second. In that team we had 50K messages that we need to handle for Black Friday (only for entry point of our system, not mentioning what we produce and consume back internally in our system, don't underestimate the value as of yet). We had multi region deployments, one overseas one in Europe. Same set of services deployed as matrix and this was working well until we got an amazing poison pill from the producing party for one topic. System went into crash loop, we can't discard it, we have DLQ (Dead-letter queue) but that is not the solution for solving this exact problem. We lost every reacknowledged message that day and needed to replay the change stream on the overseas cluster that only our team had. Problem solved. Luckily no impact other than our own time, and loss of acknowledgement time. Amazing... But time and effort went into that was incredible.
For my fellow Data Engineering/Software Engineering folks around, let me tell you the part coming is amazing. Focus into it, let me explain the power of lock-freedom, technical performance considerations and writing reliable systems.
Niche that is known
Niche is WAL. Yeah, where every data system nearly uses at some form. What is WAL?
A data log that provides durability guarantee without the storage data structures to be flushed to disk, by persisting every state change as a command to the append only log.
For more information, take a look here: https://martinfowler.com/articles/patterns-of-distributed-systems/wal.html
WAL is used mainly in databases, maybe some of your processing frameworks, but not in your services. Compared to processing frameworks, your service level guarantees are more lower in latency, or even tail latency part of the world. Thus, you can't use a framework's WAL for your near realtime services (latency 1s-5s) unless they satisfy guarantees.
All WALs out there, including SQLite, Postgres and such are using basic snapshot locking technique, e.g. SQLite's WAL buffer locking4. In addition to that Postgres does:
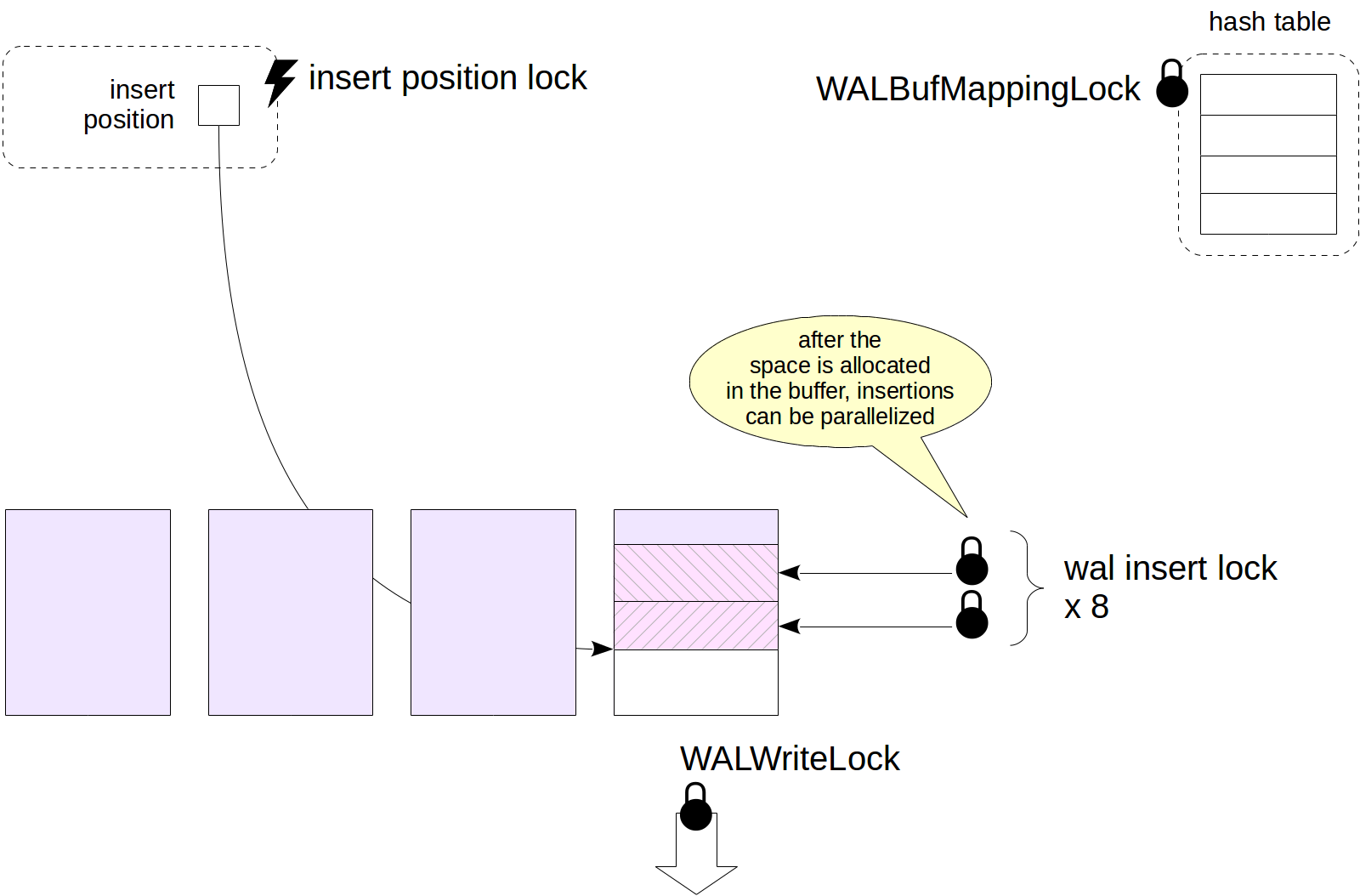
As you can see that Postgres and other databases lock the buffer pool while doing the WAL recovery or even writes in needed. Writes are not concurrent, not even parallelizable. Only one writer can write to WAL at a time. For reliability in systems we need a path doesn't block or wait for writer lock hold. Here comes my shameless plug, what if there is a WAL that can be plugged to any system that is lock-free and can able to intake batch writes and does swift recovery/replay? So, we don't end up fixing or replaying our own messages everytime we fail on some input. Think of a concurrent WAL! Nice right? But how?
NVMe, I/O and beyond
If you are not aware only a set of projects using completion-based IO for years. Initially Microsoft commercialized this IO approach where you don't wait for the IO intents' completion. That was called IOCP5, used in underlying structure of .NET and embedded throughout Windows OS. I used IO_URING6, new completion-based IO that will replace painful aio_.


I have already implemented an executor(Nuclei) there when it first publicly available. This is one thing that makes the IO fast on plenty of use cases. But not enough for WAL plumbing in my opinion.
What else do I need? Every software uses memory pages, everything that you run. There is always a lookup for memory addresses on TLB7, checks on is it in the page tables or not etc.. That said with development of storage devices and NVMe working principles, it is better that we dive into DMA8 part of the world. We don't want to copy everything into main memory and pass that to storage every single write. DMA methodology actually solves it in very efficient way so that you can write and read in streams on the opened device's buffer directly. Thus this requires pinned memory, since most NVMes sector sizes are 4KB memory pinning becomes more efficient that memory copy9. Kernel buffers FTW.
Brick in the WAL
Lock freedom, as in having lock-free programs that doesn't issue syscalls, but not necessarily wait-free programs did enormous job. Combined with everything about NVMes explained above. I could have able to write a WAL that replays multithreaded, that writes multi threaded and having nothing worse than these benchmarks. All of these code is written in Rust. This code is embeddable in any programming language without much change. From Java, to PHP, to Python... Literally every programming language can use this piece that I've developed.
Here, a set of benchmarks that shows 1 GB size of entries in various segment sizes and 1000 entry count on PCIe 3.0 NVMe which passed IOPS 4KQD1 benchmark with 66 MBytes/Sec:
-----------------------
bench_wal_write/1000data_size1000segment_entry1000entry_count
time: [42.050 s 42.179 s 42.330 s]
thrpt: [22.530 MiB/s 22.610 MiB/s 22.679 MiB/s]
Found 2 outliers among 10 measurements (20.00%)
1 (10.00%) low mild
1 (10.00%) high severe
-----------------------
bench_wal_write/1000data_size2000segment_entry1000entry_count
time: [42.274 s 42.595 s 42.915 s]
thrpt: [22.222 MiB/s 22.389 MiB/s 22.560 MiB/s]
-----------------------
bench_wal_write/1000data_size4000segment_entry1000entry_count
time: [42.629 s 43.169 s 43.774 s]
thrpt: [21.786 MiB/s 22.092 MiB/s 22.372 MiB/s]
-----------------------
Above duration also includes the data generation, so it is way less than that as you can imagine. I used EBR for in-memory wal store to implement this. Whole WAL is using skiplist to concurrently access segments of it for both concurrent read and writes.
For people who knows Rust, main WAL struct is both Send + Sync:
pub struct WAL {
cfg: WALConfig,
dir: PathBuf,
cursor: Atomic<Cursor>,
next_sequence: Arc<AtomicU64>,
segments: SkipSet<Segment>,
}As you can see this allows you to concurrently read and write without any downside while compacting in memory references to WAL segments. Simultaneously for replays my cursor(where you hold what did you read last time at when from WAL) implementation also uses DMA.
Batch writes are optimized to use DMA for WAL. One of the issues that I come across is that, I need to issue fdatasync after a batch write has been finished. Issuing too much fdatasync takes the uring boost that I get.
Since every WAL also comes with garbage collection, crash recovery (reading), and checkpointing. All of these background tasks should start also when WAL is loaded. I have put Crash recovery and checkpointing in high priority threads to make them prioritized on scheduling apart from any other task the software might have. Garbage collection happens in low priority thread and it compacts segments if it is also needed.
You might ask yourself what is the matter of using this vs a relational database or KV store. This is basically what is behind these things. Recent development in software engineering prove that embedded databases, and embedded solutions will work more performant compared to mesh of containers that are maintained and observed separately. Embedded and persistent data store is suitable for having multiple views of aggregated data and allows processing with reliability guarantees.
All these implementations made my new storage implementation called "Tundra" a specialized storage system compared to alternatives out there.
With this performant approach to data recovery for in-flight requests, events and various inputs, systems become much reliable without sacrificing the performance. I literally utilized a lot of possible performant approach with extensive set of testing to be sure that code works in varios scenarios without creating a friction to actual service logic.
This blog post was brief introduction to various concepts that I've used. Hopefully, some time I will go into detail for all the concepts that I introduced here.
But next blog post is going to be about technical standards in engineering. It will be more towards organization-wide technical standards in engineering teams, which we have applied and become successful doing so.
Thanks Denys Dorofeiev for the feedback on WAL (Write-Ahead Log) explanation in the post.
-
Pattern: Transactional outbox: - https://microservices.io/patterns/data/transactional-outbox.html ↩
-
What is a data fabric? - https://www.ibm.com/topics/data-fabric ↩
-
What is a poison pill? - https://www.confluent.io/blog/spring-kafka-can-your-kafka-consumers-handle-a-poison-pill/#poison-pill ↩
-
SQLite: Wal-Mode Blocking Locks - https://www.sqlite.org/src/doc/204dbc15a682125c/doc/wal-lock.mdl ↩
-
IOCP: I/O Completion Ports - https://learn.microsoft.com/en-us/windows/win32/fileio/i-o-completion-ports ↩
-
io_uring - https://en.wikipedia.org/wiki/Io_uring ↩
-
Translation lookaside buffer - https://en.wikipedia.org/wiki/Translation_lookaside_buffer ↩
-
Direct memory access - https://en.wikipedia.org/wiki/Direct_memory_access ↩
-
Zhu, J.; Wang, L.; Xiao, L.; Qin, G. uDMA: An Efficient User-Level DMA for NVMe SSDs. Appl. Sci. 2023, 13, 960. https://doi.org/10.3390/app13020960 ↩