
For more than 2 years Bastion is used in systems varying from multi-tenant databases in tech giants to data processing systems in food ordering services, IMDGs and more...1. Now I would like to present a use case which Bastion was thriving for a long time to achieve. Unfortunately I haven't had time to write a streaming system using Bastion until today.
Bastion is a runtime inspired from Erlang and have lightweight actor layer where actor state backed by MVCC(multi-version concurrency control) using optimistic BOCC(backward oriented concurrency control) via Lever. In addition to that Bastion's IO based on a proactor-based IO system called Nuclei which uses io_uring and its runtime fully exploits SMP with scheduler per core architecture while not giving up on fault-tolerance on the way.
Streaming experiment design
For our use case we will have:
- 3 processing stages named A, B and C
- Every stage processes source data destined for them and gathers various parts for the incoming data bag
- Every stage have 1M messages assigned based on dynamic routing.
- Every message have customer id to do correlation.
- But not used as key to group messages to partitions in Kafka
- Partitioning will make correlation easier that's why I've disabled keys completely.
- In-memory materialization table with eviction based on full aggregation on 3-way merge happens when all stages complete. This table is backed by Lever's cache-oblivious table.
- 12 partitions for both source and sink topics.
With that in mind I've created source-topic and sink-topic . All 3 million messages will be pushed to source-topic and we receive aggregated data in the sink-topic. After producing these messages for making aggregation to adapt to real life use cases, I have shuffled all of these messages to create out-of-order messages that are interleaved to make correlation stage unaware of event time.
DAG(Directed acyclic graph) definition for this system is like this:
~> process_a ~>
| \
source ~> process_b ~> ~> sink
| | / |
| ~> process_c ~> ~> processing_rate_actor
| ^
\------------------------------------|I've used Bastion's own IO system to consume data from Kafka and adapted runtime into it. Defined supervisor per processing stage + sink stage where aggregation happens with single worker under supervision tree. (I hope upcoming numbers will make "wow effect" on you, since it is only one worker for all of these processing happening...)
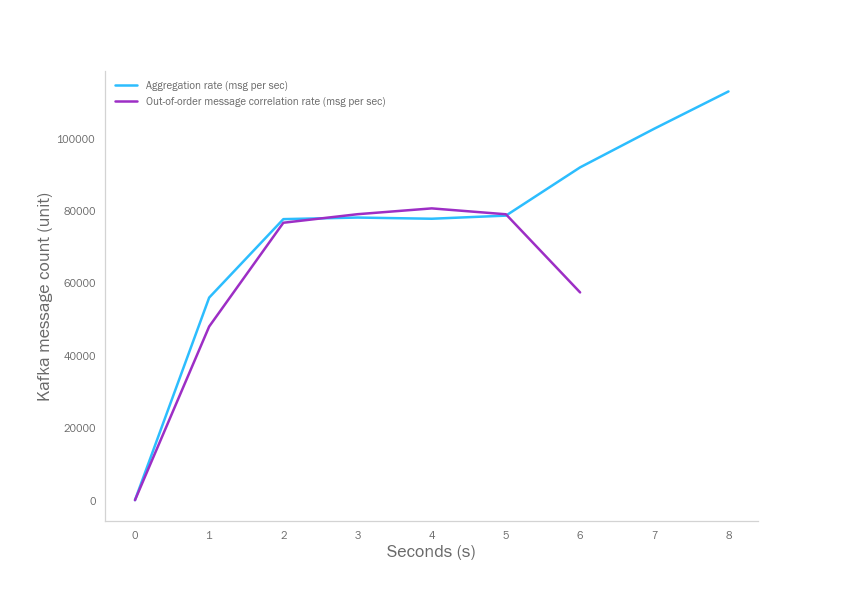
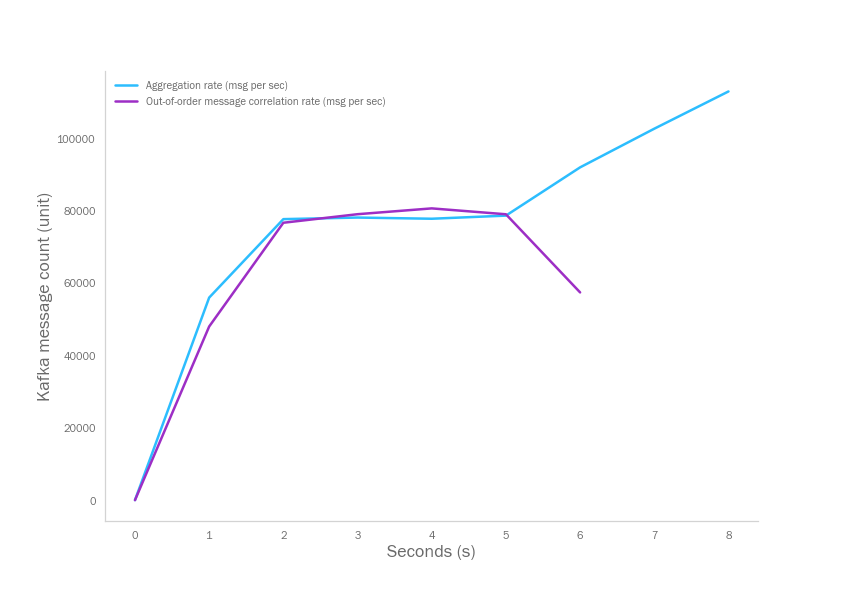
Then I started the experiment with pushing all the messages to Kafka source topic and run the draft streaming system based on Bastion. In the below table;
- Aggregation rate is the message consumption rate (including dispatching to workers and with offset commit)
- Correlation rate is the rate which we finalize merging our three different data sources and producing the final aggregation data including publishing that to Kafka.
All of the mentioned experiment is written with these dependencies:
bastion = { git = "https://github.com/bastion-rs/bastion.git" }
lever = "0.1"
clap = "2.33.3"
futures = "0.3"
futures-timer = "3.0"
serde = "1.0"
serde_json = "1.0"
rdkafka = { version = "0.26", default-features = false, features = ["libz"]}All the system above instantiated like this. Simple:
Bastion::supervisor(|sp| sink(sp, brokers.to_owned(), sink_topic.to_owned()))
.and_then(|_| Bastion::supervisor(process_c))
.and_then(|_| Bastion::supervisor(process_b))
.and_then(|_| Bastion::supervisor(process_a))
.and_then(|_| Bastion::supervisor(processing_rate_actor))
.and_then(|_| Bastion::supervisor(|sp| source(sp, brokers.to_owned(), source_topic.to_owned())))
.expect("Couldn't create supervisor chain.");I have see this as huge milestone for Bastion and our efforts for distributed computation and processing efforts. New dawn is waiting for the Bastion and we will do more throughout the time.
I've presented here a short but concise streaming architecture using Bastion, a fully out-of-order (even with its' message passing) but linearizable architecture at the application level with clear an easy use case backed by performant correlation execution. Short things are good, this is short, and more will follow I believe.
Projects
For more information about;
- Bastion: https://github.com/bastion-rs
- Lever: https://github.com/vertexclique/lever
- Nuclei: https://github.com/vertexclique/nuclei
-
Send me a DM to learn more about where and how it is used. ↩